Appearance
字符串和符号处理
尽管计算机的名称源于动词“计算”,但它们不仅在处理数字方面表现出色,在处理任何非结构化信息时也同样出色,其中最典型的例子就是文本。在 MQL 程序中,文本的使用无处不在,从程序本身的名称到交易订单中的注释都离不开它。为了在 MQL5 中处理文本,提供了内置的字符串类型,它允许你对任意长度的字符序列进行操作。
为了对字符串执行常见操作,MQL5 API 提供了丰富的函数。根据功能用途,这些函数可以大致分为以下几类:字符串初始化、字符串拼接、在字符串内搜索和替换片段、将字符串转换为字符数组、访问单个字符以及字符串格式化。
本章中的大多数函数会返回执行状态的指示:成功或错误。对于返回类型为 bool 的函数,true 通常表示成功,false 表示错误。对于返回类型为 int 的函数,值为 0 或 -1 可被视为错误,具体情况会在每个函数的描述中说明。在所有这些情况下,开发者可以了解问题的本质。为此,可以调用 GetLastError 函数获取具体的错误代码,文档中提供了所有代码及其解释的列表。需要注意的是,在收到错误标志后应立即调用 GetLastError,因为算法中后续执行的每条指令都可能导致另一个错误。
字符串的初始化与度量
从字符串类型的相关章节我们了解到,在代码中描述一个 string 类型的变量,它即可投入使用。
对于任何 string 类型的变量,会为其服务结构体分配 12 字节的空间,该结构体是字符串的内部表示形式。结构体中包含存储文本的内存地址(指针)以及一些其他元信息。文本本身也需要足够的内存,但这块缓冲区的分配存在一些不太明显的优化机制。
具体来说,我们可以在声明字符串的同时进行显式初始化,包括初始化为空字面值:
c
string s = ""; // 指向包含 '\0' 的字面值的指针在这种情况下,指针将直接指向该字面值,并且不会为缓冲区分配内存(即使字面值很长)。显然,已经为该字面值分配了静态内存,并且可以直接使用。只有当程序中的任何指令改变字符串的内容时,才会为缓冲区分配内存。例如(注意,字符串允许使用加法操作符 +):
c
int n = 1;
s += (string)n; // 指向包含 "1"'\0'[加上预留空间] 的内存的指针从这时起,字符串实际上包含文本“1”,严格来说,需要为两个字符分配内存:数字“1”和隐含的字符串结束符 '\0'。然而,系统会分配一个更大的缓冲区,并预留一些空间。
当我们声明一个没有初始值的变量时,编译器仍然会对其进行隐式初始化,不过在这种情况下,它会被初始化为一个特殊的 NULL 值:
c
string z; // 未为指针分配内存,指针 = NULL这样的字符串每个结构体仅需 12 字节,并且指针不指向任何地方,这就是 NULL 的含义。
在 MQL5 编译器的未来版本中,这种行为可能会改变,对于空字符串,可能会始终初始分配一小片内存,并提供一些预留空间。
除了这些内部特性外,string 类型的变量与其他类型的变量没有区别。然而,由于字符串的长度可能是可变的,更重要的是,在算法执行过程中它们的长度可能会发生变化,这可能会对内存分配的效率和性能产生不利影响。
例如,如果程序在某个时刻需要向字符串中添加一个新单词,可能会发现为该字符串分配的内存不足。然后,MQL 程序的执行环境(用户无法察觉)会找到一个更大的新空闲内存块,并将旧值连同新添加的单词一起复制到那里。之后,字符串的服务结构体中的旧地址将被新地址替换。
如果存在许多这样的操作,由于复制操作导致的速度减慢可能会变得明显,此外,程序内存还会出现碎片化问题:复制后释放的旧的小内存区域会形成空隙,这些空隙的大小不适合存储大字符串,从而导致内存浪费。当然,终端能够控制这种情况并重新组织内存,但这也需要付出一定的代价。
解决这个问题最有效的方法是提前显式指定字符串缓冲区的大小,并使用内置的 MQL5 API 函数对其进行初始化,我们将在本节后面部分介绍这些函数。
这种优化的基础在于,分配的内存大小可能会超过字符串当前(以及潜在的未来)的长度,字符串的长度由文本中的第一个空字符决定。因此,我们可以为 100 个字符分配一个缓冲区,但从一开始就在最前面放置 '\0',这将得到一个长度为零的字符串("")。
当然,在这种情况下,假设程序员能够大致提前计算出字符串的预期长度或其增长速度。
由于 MQL5 中的字符串基于双字节字符(这确保了对 Unicode 的支持),字符串和缓冲区的字符大小应乘以 2 才能得到占用和分配的内存字节数。
本节末尾将给出使用所有函数的综合示例(StringInit.mq5)。
bool StringInit(string &variable, int capacity = 0, ushort character = 0)
StringInit 函数用于初始化(分配和填充内存)以及反初始化(释放内存)字符串。要处理的变量通过第一个参数传递。
如果 capacity 参数大于 0,则为字符串分配一个指定大小的缓冲区(内存区域),并用 character 字符填充。如果 character 为 0,那么字符串的长度将为零,因为第一个字符是结束符。
如果 capacity 参数为 0,则释放先前分配的内存。变量的状态将与刚声明但未初始化时相同(指向缓冲区的指针为 NULL)。更简单地说,将字符串变量设置为 NULL 也能达到同样的效果。
该函数返回成功指示(true)或错误指示(false)。
bool StringReserve(string &variable, uint capacity)
StringReserve 函数增加或减少字符串变量的缓冲区大小,至少达到 capacity 参数中指定的字符数。如果 capacity 值小于当前字符串的长度,该函数不执行任何操作。实际上,缓冲区的大小可能会比请求的大:执行环境出于对字符串未来操作效率的考虑会这样做。因此,如果使用减小缓冲区大小的值调用该函数,它可能会忽略该请求并仍然返回 true(“无错误”)。
当前缓冲区的大小可以使用 StringBufferLen 函数获取(见下文)。
如果成功,该函数返回 true,否则返回 false。
与 StringInit 不同,StringReserve 函数不会更改字符串的内容,也不会用字符填充它。
bool StringFill(string &variable, ushort character)
StringFill 函数用 character 字符填充指定的字符串变量,填充范围为其当前的整个长度(直到第一个空字符)。如果为字符串分配了缓冲区,则在原位进行修改,无需中间的换行和复制操作。
该函数返回成功指示(true)或错误指示(false)。
int StringBufferLen(const string &variable)
该函数返回为字符串变量 variable 分配的缓冲区大小。
请注意,对于用字面值初始化的字符串,最初不会分配缓冲区,因为指针指向该字面值。因此,即使 StringLen 函数(见下文)返回的字符串长度可能更大,该函数仍将返回 0。
值 -1 表示该字符串属于客户端终端且不能被更改。
bool StringSetLength(string &variable, uint length)
该函数为字符串变量 variable 设置指定的字符长度 length。length 的值不能大于字符串的当前长度。换句话说,该函数只允许缩短字符串,而不允许延长它。当调用 StringAdd 函数或执行加法操作 + 时,字符串的长度会自动增加。
StringSetLength 函数的等效操作是调用 StringSetCharacter(variable, length, 0)(见“处理符号和代码页”部分)。
如果在调用该函数之前已经为字符串分配了缓冲区,该函数不会更改它。如果字符串没有缓冲区(它指向一个字面值),减小长度会导致分配一个新的缓冲区,并将缩短后的字符串复制到其中。
该函数在成功时返回 true,在失败时返回 false。
int StringLen(const string text)
该函数返回字符串 text 中的字符数。字符串结束符 \0 不计算在内。
请注意,参数是按值传递的,因此不仅可以计算变量中字符串的长度,还可以计算任何其他中间值(计算结果或字面值)的字符串长度。
为了演示上述函数,创建了 StringInit.mq5 脚本。它使用了 PRT 宏的一个特殊版本 PRTE,该宏将表达式的结果解析为 true 或 false,如果是 false,还会额外输出错误代码:
c
#define PRTE(A) Print(#A, "=", (A) ? "true" : "false:" + (string)GetLastError())为了将字符串及其当前度量信息(字符串长度和缓冲区大小)输出到日志进行调试,实现了 StrOut 函数:
c
void StrOut(const string &s)
{
Print("'", s, "' [", StringLen(s), "] ", StringBufferLen(s));
}它使用了内置的 StringLen 和 StringBufferLen 函数。
测试脚本在 OnStart 函数中对一个字符串执行了一系列操作:
c
void OnStart()
{
string s = "message";
StrOut(s);
PRTE(StringReserve(s, 100)); // 成功,但我们得到的缓冲区比请求的大:260
StrOut(s);
PRTE(StringReserve(s, 500)); // 成功,缓冲区增加到 500
StrOut(s);
PRTE(StringSetLength(s, 4)); // 成功:字符串被缩短
StrOut(s);
s += "age";
PRTE(StringReserve(s, 100)); // 成功:缓冲区保持为 500
StrOut(s);
PRTE(StringSetLength(s, 8)); // 失败:不支持通过 StringSetLength 延长字符串
StrOut(s); // via StringSetLength
PRTE(StringInit(s, 8, '$')); // 成功:通过填充增加字符串长度
StrOut(s); // 缓冲区保持不变
PRTE(StringFill(s, 0)); // 成功:字符串因填充 0 而变为空字符串,缓冲区不变
StrOut(s);
PRTE(StringInit(s, 0)); // 成功:字符串清零,包括缓冲区
// 我们也可以直接写 s = NULL;
StrOut(s);
}该脚本将在日志中记录以下消息:
'message' [7] 0
StringReserve(s,100)=true
'message' [7] 260
StringReserve(s,500)=true
'message' [7] 500
StringSetLength(s,4)=true
'mess' [4] 500
StringReserve(s,10)=true
'message' [7] 500
StringSetLength(s,8)=false:5035
'message' [7] 500
StringInit(s,8,'$')=true
'$$$$$$$$' [8] 500
StringFill(s,0)=true
'' [0] 500
StringInit(s,0)=true
'' [0] 0请注意,调用 StringSetLength 并尝试增加字符串长度时,以错误 5035(ERR_STRING_SMALL_LEN)结束。
字符串拼接
字符串拼接可能是最常见的字符串操作了。在 MQL5 中,可以使用 + 或 += 运算符来完成拼接。+ 运算符会连接两个字符串(+ 运算符左右两边的操作数),并创建一个临时的拼接字符串,这个临时字符串可以赋值给目标变量,或者传递给表达式的其他部分(比如函数调用)。+= 运算符则是将 += 运算符右边的字符串追加到左边的字符串(变量)上。
除此之外,MQL5 API 还提供了几个用于从其他字符串或其他类型的元素组合成字符串的函数。
函数的使用示例在 StringAdd.mq5 脚本中给出,在对这些函数进行描述之后会对该脚本进行讲解。
bool StringAdd(string &variable, const string addition)
该函数将指定的 addition 字符串追加到字符串变量 variable 的末尾。只要有可能,系统会使用字符串变量已有的缓冲区(如果其大小足以容纳拼接后的结果),而无需重新分配内存或复制字符串。
该函数等同于 variable += addition 运算符,时间开销和内存消耗大致相同。
函数成功时返回 true,出错时返回 false。
int StringConcatenate(string &variable, void argument1, void argument2 [, void argumentI...])
该函数将两个或更多内置类型的参数转换为字符串表示形式,并将它们连接到 variable 字符串中。参数从函数的第二个参数开始传递。不支持将数组、结构体、对象、指针作为参数。
参数的数量必须在 2 到 63 之间。
字符串参数会按原样添加到结果变量中。
double 类型的参数会以最高精度进行转换(最多 16 位有效数字),如果科学计数法更紧凑,会选择使用科学计数法。float 类型的参数会显示 5 个字符。
datetime 类型的值会转换为包含所有日期和时间字段的字符串(“YYYY.MM.DD hh:mm:ss”)。
枚举、单字节和双字节字符会作为整数输出。
color 类型的值会显示为 “R,G,B” 三个分量组成的三元组,或者显示为颜色名称(如果在标准 Web 颜色列表中存在)。
在转换 bool 类型的值时,会使用字符串 “true” 或 “false”。
StringConcatenate 函数返回结果字符串的长度。
StringConcatenate 函数旨在从接收变量以外的其他源(变量、表达式)构建字符串。不建议通过调用 StringConcatenate(variable, variable,...) 将新的数据块连接到同一字符串上。这种函数调用没有经过优化,与 + 运算符和 StringAdd 函数相比,速度极慢。
StringAdd 和 StringConcatenate 函数在 StringAdd.mq5 脚本中进行了测试,该脚本使用了 PRTE 宏以及上一节中的辅助函数 StrOut。
c
void OnStart()
{
string s = "message";
StrOut(s);
PRTE(StringAdd(s, "r"));
StrOut(s);
PRTE(StringConcatenate(s, M_PI * 100, " ", clrBlue, PRICE_CLOSE));
StrOut(s);
}执行该脚本后,日志中会显示以下内容:
'message' [7] 0
StringAdd(s,r)=true
'messager' [8] 260
StringConcatenate(s,M_PI*100, ,clrBlue,PRICE_CLOSE)=true
'314.1592653589793 clrBlue1' [26] 260该脚本还包含头文件 StringBenchmark.mqh,其中有 benchmark 类。它为脚本中实现的派生类提供了一个框架,用于测量各种字符串添加方法的性能。特别是,它们确保使用 + 运算符和 StringAdd 函数添加字符串的性能是可比的。这部分内容留给读者自行学习。
此外,本书还附带了 StringReserve.mq5 脚本:它直观地比较了在使用或不使用缓冲区(StringReserve)的情况下添加字符串的速度。
字符串比较
在 MQL5 中比较字符串时,可以使用标准的比较运算符,特别是 ==、!=、>、<。所有这些运算符都是逐字符进行比较的,并且区分大小写。
每个字符都有一个 Unicode 编码,它是一个 ushort 类型的整数。相应地,首先比较两个字符串的第一个字符的编码,然后是第二个字符的编码,依此类推,直到出现第一个不匹配的字符或者到达其中一个字符串的末尾。
例如,字符串 “ABC” 小于 “abc”,因为在字符表中大写字母的编码低于相应小写字母的编码(在第一个字符上我们就得到 “A” < “a”)。如果字符串开头的字符匹配,但其中一个字符串比另一个长,那么较长的字符串被认为更大(“ABCD” > “ABC”)。
这样的字符串关系形成了字典序。当字符串 “A” 小于字符串 “B”(“A” < “B”)时,就说 “A” 在 “B” 之前。
要熟悉字符编码,可以使用标准的 Windows 应用程序“字符映射表”。在其中,字符按编码递增的顺序排列。除了包含许多国家语言的通用 Unicode 表之外,还有代码页:具有单字节字符编码的 ANSI 标准表,不同语言或语言组的代码页是不同的。我们将在“处理符号和代码页”部分更详细地探讨这个问题。
字符表中编码从 0 到 127 的初始部分对于所有语言都是相同的。这部分内容如下表所示:
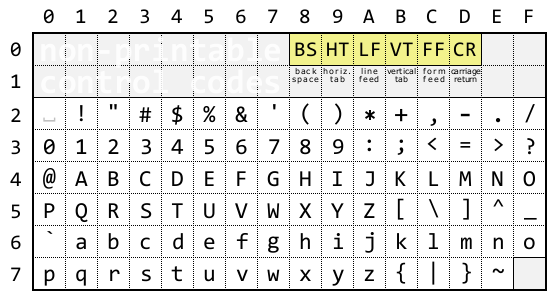
ASCII 字符编码表
要获取字符编码,取左边的十六进制数字(字符所在的行号)并加上顶部的数字(字符所在的列号):结果是一个十六进制数。例如,对于 !,左边是 2,顶部是 1,这意味着字符编码是 0x21,即十进制的 33。
编码小于等于 32 的是控制码。其中,特别可以找到制表符(编码 0x9)、换行符(编码 0xA)和回车符(编码 0xD)。
在 Windows 文本文件中,连续的两个字符 0xD 0xA 用于换行。我们在“字符类型”部分已经了解了相应的 MQL5 字面量:0xA 可以表示为 '\n',0xD 表示为 '\r'。制表符 0x9 也有自己的表示形式:'\t'。
MQL5 API 提供了 StringCompare 函数,它允许在比较字符串时禁用区分大小写的功能。
int StringCompare(const string &string1, const string &string2, const bool case_sensitive = true)
该函数比较两个字符串,并返回三个值之一:如果第一个字符串“大于”第二个字符串,则返回 +1;如果两个字符串“相等”,则返回 0;如果第一个字符串“小于”第二个字符串,则返回 -1。“大于”“小于”和“等于”的概念取决于 case_sensitive 参数。
当 case_sensitive 参数等于 true(这是默认值)时,比较是区分大小写的,大写字母被认为大于相同的小写字母。这与根据字符编码的标准字典序相反。
在区分大小写的情况下,StringCompare 函数使用的大写字母和小写字母的顺序与字典序不同。例如,我们知道 “A” < “a” 这个关系是正确的,其中 < 运算符是根据字符编码来判断的。因此,大写单词在假设的字典(数组)中应该出现在具有相同小写字母的单词之前。然而,当使用 StringCompare("A", "a") 函数比较 “A” 和 “a” 时,我们得到 +1,这意味着 “A” 大于 “a”。因此,在排序后的字典中,以小写字母开头的单词将首先出现,只有在它们之后才会出现以大写字母开头的单词。
换句话说,该函数按字母顺序对字符串进行排序。此外,在区分大小写模式下,还有一个额外的规则:如果存在仅大小写不同的字符串,那么包含大写字母的字符串将跟随在具有相同小写字母的字符串之后(在单词的相同位置)。
如果 case_sensitive 参数等于 false,则字母不区分大小写,所以字符串 “A” 和 “a” 被认为是相等的,函数返回 0。
你可以使用 StringCompare.mq5 脚本检查 StringCompare 函数和比较运算符的不同比较结果。
c
void OnStart()
{
PRT(StringCompare("A", "a")); // 1, 这意味着 "A" > "a" (!)
PRT(StringCompare("A", "a", false)); // 0, 这意味着 "A" == "a"
PRT("A" > "a"); // false, "A" < "a"
PRT(StringCompare("x", "y")); // -1, 这意味着 "x" < "y"
PRT("x" > "y"); // false, "x" < "y"
...
}在“函数模板”部分,我们创建了一个模板化的快速排序算法。让我们将它转换为一个模板类,并使用它进行几种排序选项:使用比较运算符,以及使用 StringCompare 函数(区分大小写和不区分大小写)。我们将新的 QuickSortT 类放在 QuickSortT.mqh 头文件中,并将其连接到测试脚本 StringCompare.mq5。
排序 API 几乎没有变化。
c
template<typename T>
class QuickSortT
{
public:
void Swap(T &array[], const int i, const int j)
{
...
}
virtual int Compare(T &a, T &b)
{
return a > b ? +1 : (a < b ? -1 : 0);
}
void QuickSort(T &array[], const int start = 0, int end = INT_MAX)
{
...
for(int i = start; i <= end; i++)
{
//if(!(array[i] > array[end]))
if(Compare(array[i], array[end]) <= 0)
{
Swap(array, i, pivot++);
}
}
...
}
};主要的区别是我们添加了一个虚方法 Compare,默认情况下它使用 > 和 < 运算符进行比较,并且像 StringCompare 一样返回 +1、-1 或 0。现在 QuickSort 方法中使用 Compare 方法而不是简单的比较,并且必须在子类中重写它,以便使用 StringCompare 函数或任何其他比较方式。
特别是,在 StringCompare.mq5 文件中,我们实现了以下从 QuickSortT<string> 派生的“比较器”类:
c
class SortingStringCompare : public QuickSortT<string>
{
const bool caseEnabled;
public:
SortingStringCompare(const bool sensitivity = true) :
caseEnabled(sensitivity) { }
virtual int Compare(string &a, string &b) override
{
return StringCompare(a, b, caseEnabled);
}
};构造函数接收 1 个参数,该参数指定考虑(true)或忽略(false)大小写的字符串比较标志。字符串比较本身在重定义的虚方法 Compare 中完成,该方法使用给定的参数和设置调用 StringCompare 函数。
为了测试排序,我们需要一组包含大写和小写字母的字符串。我们可以自己生成:只需开发一个类,对于给定的集合长度(字符串),对预定义集合(字母表)中的字符进行排列(可重复)。例如,可以将范围限制在小写字母 “abcABC”,即三个首字母的大小写形式,并从它们生成所有可能的 2 个字符的字符串。
PermutationGenerator 类在 PermutationGenerator.mqh 文件中提供,留给读者自行学习。这里我们仅展示它的公共接口。
c
class PermutationGenerator
{
public:
struct Result
{
int indices[]; // 集合每个位置上元素的索引,即
}; // 例如,字符串每个位置上 "字母表" 中字母的编号
PermutationGenerator(const int length, const int elements);
SimpleArray<Result> *run();
};创建生成器对象时,必须指定生成集合的长度 length(在我们的例子中,这将是字符串的长度,即 2)以及组成集合的不同元素的数量(在我们的例子中,这是唯一字母的数量,即 6)。使用这样的输入数据,应该得到 6 * 6 = 36 种字符串变体。
实际的生成过程由 run 方法执行。使用模板类 SimpleArray 来返回结果数组,我们在“方法模板”部分讨论过它。在这种情况下,它由 result 结构类型进行参数化。
生成器的调用以及根据从它接收到的排列数组(以所有可能字符串在每个位置上的字母索引的形式)实际创建字符串的操作在辅助函数 GenerateStringList 中进行。
c
void GenerateStringList(const string symbols, const int len, string &result[])
{
const int n = StringLen(symbols); // 字母表长度,唯一字符数
PermutationGenerator g(len, n);
SimpleArray<PermutationGenerator::Result> *r = g.run();
ArrayResize(result, r.size());
// 遍历所有接收到的字符排列
for(int i = 0; i < r.size(); ++i)
{
string element;
// 遍历字符串中的所有字符
for(int j = 0; j < len; ++j)
{
// 将字母表中的一个字母(根据其索引)添加到字符串中
element += ShortToString(symbols[r[i].indices[j]]);
}
result[i] = element;
}
}这里我们使用了几个我们还不熟悉的函数(ArrayResize、ShortToString),但我们很快就会学到它们。目前,我们只需要知道 ShortToString 函数根据 ushort 类型的字符编码返回一个由单个字符组成的字符串。使用 += 运算符,我们将这些单个字符组成的字符串连接成每个结果字符串。回想一下,为字符串定义了 [] 运算符,所以表达式 symbols[k] 将返回 symbols 字符串的第 k 个字符。当然,k 本身可以是一个整数表达式,这里 r[i].indices[j] 是指从 r 数组的第 i 个元素中读取字符串第 j 个位置的“字母表”字符的索引。
每个接收到的字符串都存储在数组参数 result 中。
让我们在 OnStart 函数中应用这些信息。
c
void OnStart()
{
...
string messages[];
GenerateStringList("abcABC", 2, messages);
Print("Original data[", ArraySize(messages), "]:");
ArrayPrint(messages);
Print("Default case-sensitive sorting:");
QuickSortT<string> sorting;
sorting.QuickSort(messages);
ArrayPrint(messages);
Print("StringCompare case-insensitive sorting:");
SortingStringCompare caseOff(false);
caseOff.QuickSort(messages);
ArrayPrint(messages);
Print("StringCompare case-sensitive sorting:");
SortingStringCompare caseOn(true);
caseOn.QuickSort(messages);
ArrayPrint(messages);
}该脚本首先将所有字符串选项获取到 messages 数组中,然后以三种模式对其进行排序:使用内置的比较运算符,使用 StringCompare 函数的不区分大小写模式,以及使用 StringCompare 函数的区分大小写模式。
我们将得到以下日志输出:
Original data[36]:
[ 0] "aa" "ab" "ac" "aA" "aB" "aC" "ba" "bb" "bc" "bA" "bB" "bC" "ca" "cb" "cc" "cA" "cB" "cC"
[18] "Aa" "Ab" "Ac" "AA" "AB" "AC" "Ba" "Bb" "Bc" "BA" "BB" "BC" "Ca" "Cb" "Cc" "CA" "CB" "CC"
Default case-sensitive sorting:
[ 0] "AA" "AB" "AC" "Aa" "Ab" "Ac" "BA" "BB" "BC" "Ba" "Bb" "Bc" "CA" "CB" "CC" "Ca" "Cb" "Cc"
[18] "aA" "aB" "aC" "aa" "ab" "ac" "bA" "bB" "bC" "ba" "bb" "bc" "cA" "cB" "cC" "ca" "cb" "cc"
StringCompare case-insensitive sorting:
[ 0] "AA" "Aa" "aA" "aa" "AB" "aB" "Ab" "ab" "aC" "AC" "Ac" "ac" "BA" "Ba" "bA" "ba" "BB" "bB"
[18] "Bb" "bb" "bC" "BC" "Bc" "bc" "CA" "Ca" "cA" "ca" "CB" "cB" "Cb" "cb" "cC" "CC" "Cc" "cc"
StringCompare case-sensitive sorting:
[ 0] "aa" "aA" "Aa" "AA" "ab" "aB" "Ab" "AB" "ac" "aC" "Ac" "AC" "ba" "bA" "Ba" "BA" "bb" "bB"
[18] "Bb" "BB" "bc" "bC" "Bc" "BC" "ca" "cA" "Ca" "CA" "cb" "cB" "Cb" "CB" "cc" "cC" "Cc" "CC"输出显示了这三种模式的差异。
更改字符大小写和去除空白字符
处理文本时常常会用到一些标准操作,比如将所有字符转换为大写或小写,以及去除字符串开头或结尾处多余的空白字符(例如空格)。为此,MQL5 API 提供了四个相应的函数。这些函数都会在原位修改字符串,也就是说,直接在已分配的可用缓冲区中进行修改。
所有这些函数的输入参数都是对字符串的引用,即只能将变量(而不是表达式)传递给它们,并且不能是常量变量,因为这些函数需要修改参数。
对所有函数进行测试的脚本会在相关描述之后给出。
bool StringToLower(string &variable)
bool StringToUpper(string &variable)
这些函数将指定字符串的所有字符转换为相应的大小写:StringToLower 转换为小写字母,StringToUpper 转换为大写字母。这包括对 Windows 系统级别支持的各种国家语言的处理。
如果操作成功,函数返回 true;如果出错,则返回 false。
int StringTrimLeft(string &variable)
int StringTrimRight(string &variable)
StringTrimLeft 函数会去除字符串开头的回车符('\r')、换行符('\n')、空格(' ')、制表符('\t')以及其他一些不可显示的字符;StringTrimRight 函数则会去除字符串结尾的这些字符。如果字符串内部(在可显示字符之间)存在空白字符,它们将被保留。
函数返回去除的字符数量。
StringModify.mq5 文件演示了上述函数的操作:
c
void OnStart()
{
string text = " \tAbCdE F1 ";
// ↑ ↑ ↑
// | | └2个空格
// | └空格
// └2个空格和制表符
PRT(StringToLower(text)); // 'true'
PRT(text); // ' \tabcde f1 '
PRT(StringToUpper(text)); // 'true'
PRT(text); // ' \tABCDE F1 '
PRT(StringTrimLeft(text)); // '3'
PRT(text); // 'ABCDE F1 '
PRT(StringTrimRight(text)); // '2'
PRT(text); // 'ABCDE F1'
PRT(StringTrimRight(text)); // '0' (没有其他可删除的内容了)
PRT(text); // 'ABCDE F1'
// ↑
// └内部的空格被保留
string russian = "Russian text";
PRT(StringToUpper(russian)); // 'true'
PRT(russian); // 'RUSSIAN TEXT'
string german = "straßenführung";
PRT(StringToUpper(german)); // 'true'
PRT(german); // 'STRAßENFÜHRUNG'
}查找、替换和提取字符串片段
在处理字符串时,最常用的操作或许就是查找和替换片段,以及提取片段。在这部分内容中,我们会学习 MQL5 API 里能够解决这些问题的函数。这些函数的使用示例都汇总在 StringFindReplace.mq5 文件里。
int StringFind(string value, string wanted, int start = 0)
此函数从 start 位置开始,在字符串 value 里查找子字符串 wanted。若找到该子字符串,函数会返回其起始位置,字符串中的字符编号从 0 开始;若未找到,则返回 -1。这两个参数都是按值传递的,这意味着不仅可以处理变量,还能处理计算的中间结果(表达式、函数调用)。
搜索是基于字符的严格匹配进行的,也就是区分大小写。若要进行不区分大小写的搜索,就得先使用 StringToLower 或 StringToUpper 把源字符串转换为统一的大小写。
我们尝试用 StringFind 函数统计文本中所需子字符串出现的次数。为此,我们编写一个辅助函数 CountSubstring,它会在循环里调用 StringFind,并逐步移动最后一个参数 start 中的搜索起始位置。只要能找到子字符串的新出现位置,循环就会继续执行。
c
int CountSubstring(const string value, const string wanted)
{
// 由于循环开始时会自增,所以先回退一个位置
int cursor = -1;
int count = -1;
do
{
++count;
++cursor; // 从下一个位置继续搜索
// 获取下一个子字符串的位置,若没有匹配则返回 -1
cursor = StringFind(value, wanted, cursor);
}
while(cursor > -1);
return count;
}需要注意的是,上述实现查找的子字符串是可以重叠的。这是因为在开始查找下一个出现位置之前,当前位置会增加 1(++cursor)。所以,当在字符串 "AAAAA" 中搜索子字符串 "AAA" 时,会找到 3 个匹配项。搜索的技术要求可能和这种行为有所不同。特别是,有一种做法是在之前找到的片段结束位置之后继续搜索。在这种情况下,就需要修改算法,让 cursor 以等于 StringLen(wanted) 的步长移动。
我们在 OnStart 函数中对不同的参数调用 CountSubstring 函数。
c
void OnStart()
{
string abracadabra = "ABRACADABRA";
PRT(CountSubstring(abracadabra, "A")); // 5
PRT(CountSubstring(abracadabra, "D")); // 1
PRT(CountSubstring(abracadabra, "E")); // 0
PRT(CountSubstring(abracadabra, "ABRA")); // 2
...
}int StringReplace(string &variable, const string wanted, const string replacement)
该函数会把字符串 variable 中所有找到的 wanted 子字符串替换成 replacement 子字符串。
函数会返回替换的次数,若出错则返回 -1。可以通过调用 GetLastError 函数获取错误代码。特别是,可能会出现内存不足的错误,或者将未初始化的字符串(NULL)作为参数使用。variable 和 wanted 参数必须是长度不为零的字符串。
若将空字符串 "" 作为 replacement 参数,那么所有 wanted 的出现位置都会从原始字符串中直接删除。
若没有进行替换,函数的结果为 0。
我们通过 StringFindReplace.mq5 示例来查看 StringReplace 函数的实际运行情况。
c
string abracadabra = "ABRACADABRA";
...
PRT(StringReplace(abracadabra, "ABRA", "-ABRA-")); // 2
PRT(StringReplace(abracadabra, "CAD", "-")); // 1
PRT(StringReplace(abracadabra, "", "XYZ")); // -1, 错误
PRT(GetLastError()); // 5040, ERR_WRONG_STRING_PARAMETER
PRT(abracadabra); // '-ABRA---ABRA-'
...接下来,我们使用 StringReplace 函数尝试解决在处理任意文本时遇到的一个任务。我们要确保某个分隔符字符始终作为单个字符使用,也就是多个这样的字符序列必须替换为一个。通常,这指的是单词之间的空格,但在技术数据中可能会有其他分隔符。我们针对分隔符 - 来测试我们的程序。
我们把这个算法实现为一个单独的函数 NormalizeSeparatorsByReplace:
c
int NormalizeSeparatorsByReplace(string &value, const ushort separator = ' ')
{
const string single = ShortToString(separator);
const string twin = single + single;
int count = 0;
int replaced = 0;
do
{
replaced = StringReplace(value, twin, single);
if(replaced > 0) count += replaced;
}
while(replaced > 0);
return count;
}该程序会在 do - while 循环中尝试将两个分隔符的序列替换为一个,只要 StringReplace 函数返回的值大于 0(即还有需要替换的内容),循环就会继续。函数会返回总共进行的替换次数。
在 OnStart 函数中,我们对包含多个 - 字符的字符串进行“清理”。
c
...
string copy1 = "-" + abracadabra + "-";
string copy2 = copy1;
PRT(copy1); // '--ABRA---ABRA--'
PRT(NormalizeSeparatorsByReplace(copy1, '-')); // 4
PRT(copy1); // '-ABRA-ABRA-'
PRT(StringReplace(copy1, "-", "")); // 1
PRT(copy1); // 'ABRAABRA'
...int StringSplit(const string value, const ushort separator, string &result[])
此函数会根据给定的分隔符将传入的字符串 value 分割成多个子字符串,并将它们存入 result 数组。函数会返回得到的子字符串的数量,若出错则返回 -1。
若字符串中没有分隔符,数组将只有一个元素,其值等于整个字符串。
若源字符串为空或为 NULL,函数将返回 0。
为了演示这个函数的操作,我们用 StringSplit 以一种新的方式解决之前的问题。为此,我们编写函数 NormalizeSeparatorsBySplit。
c
int NormalizeSeparatorsBySplit(string &value, const ushort separator = ' ')
{
const string single = ShortToString(separator);
string elements[];
const int n = StringSplit(value, separator, elements);
ArrayPrint(elements); // 调试用
StringFill(value, 0); // 结果将替换原始字符串
for(int i = 0; i < n; ++i)
{
// 空字符串表示分隔符,只有在前一个字符串不为空(即也不是分隔符)时才添加
if(elements[i] == "" && (i == 0 || elements[i - 1] != ""))
{
value += single;
}
else // 其他所有字符串按原样连接
{
value += elements[i];
}
}
return n;
}当源文本中分隔符连续出现时,StringSplit 输出数组中对应的元素会是一个空字符串 ""。此外,如果文本以分隔符开头,数组开头会有一个空字符串;如果文本以分隔符结尾,数组末尾会有一个空字符串。
要得到“清理”后的文本,需要将数组中所有非空字符串添加进来,并用单个分隔符字符将它们“粘合”在一起。而且,只有那些前一个数组元素也不为空的空元素才应转换为分隔符。
当然,这只是实现此功能的一种可能方式。我们在 OnStart 函数中对其进行测试。
c
...
string copy2 = "-" + abracadabra + "-"; // '--ABRA---ABRA--'
PRT(NormalizeSeparatorsBySplit(copy2, '-')); // 8
// 函数内部的分割数组调试输出:
// "" "" "ABRA" "" "" "ABRA" "" ""
PRT(copy2); // '-ABRA-ABRA-'string StringSubstr(string value, int start, int length = -1)
该函数从传入的文本 value 中提取从指定位置 start 开始、长度为 length 的子字符串。起始位置可以是从 0 到字符串长度减 1。若 length 为 -1 或者大于从 start 到字符串末尾的字符数,将完整提取字符串的剩余部分。
若参数不正确,函数会返回一个子字符串或空字符串。
我们来看它是如何工作的。
c
PRT(StringSubstr("ABRACADABRA", 4, 3)); // 'CAD'
PRT(StringSubstr("ABRACADABRA", 4, 100)); // 'CADABRA'
PRT(StringSubstr("ABRACADABRA", 4)); // 'CADABRA'
PRT(StringSubstr("ABRACADABRA", 100)); // ''处理符号和代码页
由于字符串是由字符组成的,有时在字符的整数编码层面上操作字符串中的单个字符或字符组是必要的,或者会更加方便。例如,需要逐个读取或替换字符,或者将它们转换为整数编码数组,以便通过通信协议传输,或者传递给动态链接库(DLL)的第三方编程接口。在所有这些情况下,将字符串作为文本传递可能会遇到各种困难:
- 确保正确的编码(编码方式有很多种,具体的选择取决于操作系统的区域设置、程序设置、与之通信的服务器的配置等等)
- 将本国语言字符从本地文本编码转换为 Unicode 编码,反之亦然
- 以统一的方式进行内存的分配和释放
使用整数编码数组(实际上,这种使用方式产生的是字符串的二进制表示,而非文本表示)可以简化这些问题。
MQL5 API 提供了一组函数,用于在考虑编码特性的情况下操作单个字符或字符组。
MQL5 中的字符串包含采用双字节 Unicode 编码的字符。这在一个(非常庞大的)字符表中为各种不同的国家字母表提供了通用支持。两个字节可以对 65535 个元素进行编码。
默认的字符类型是 ushort。然而,如果有必要,字符串可以转换为特定语言编码的单字节 uchar 字符序列。这种转换可能会伴随一些信息的丢失(特别是,不在本地化字符表中的字母可能会“丢失”变音符号,甚至“变成”某种替代字符:根据上下文的不同,它可能会有不同的显示方式,但通常显示为 ? 或一个方块字符)。
为了避免处理可能包含任意字符的文本时出现问题,建议始终使用 Unicode。如果某些要与您的 MQL 程序集成的外部服务或程序不支持 Unicode,或者如果文本从一开始就只打算存储有限的一组字符(例如,仅包含数字和拉丁字母),则可以例外。
在转换为单字节字符或从单字节字符转换时,MQL5 API 默认使用 ANSI 编码,具体取决于当前的 Windows 设置。不过,开发人员可以指定不同的代码表(请参阅后面的函数 CharArrayToString、StringToCharArray)。
下面描述的函数的使用示例在 StringSymbols.mq5 文件中给出。
bool StringSetCharacter(string &variable, int position, ushort character)
该函数将字符串 variable 中 position 位置的字符更改为传入的 character 值。位置编号必须在 0 到字符串长度(StringLen)减 1 之间。
如果要写入的字符为 0,它将指定一个新的行结尾(充当终止零),即字符串的长度变为等于 position。为字符串分配的缓冲区大小不会改变。
如果 position 参数等于字符串的长度,并且要写入的字符不等于 0,那么该字符将被添加到字符串中,其长度增加 1。这等同于表达式:variable += ShortToString(character)。
函数成功完成时返回 true,出错时返回 false。
c
void OnStart()
{
string numbers = "0123456789";
PRT(numbers);
PRT(StringSetCharacter(numbers, 7, 0)); // 在第 7 个字符处截断
PRT(numbers); // 0123456
PRT(StringSetCharacter(numbers, StringLen(numbers), '*')); // 添加 '*'
PRT(numbers); // 0123456*
...
}ushort StringGetCharacter(string value, int position)
该函数返回字符串中指定位置 position 处的字符编码。位置编号必须在 0 到字符串长度(StringLen)减 1 之间。如果出错,函数将返回 0。
该函数等同于使用 [] 运算符进行编写:value[position]。
c
string numbers = "0123456789";
PRT(StringGetCharacter(numbers, 5)); // 53 = 字符 '5' 的编码
PRT(numbers[5]); // 53 - 结果相同string CharToString(uchar code)
该函数将字符的 ANSI 编码转换为单字符字符串。根据设置的 Windows 代码页,编码的上半部分(大于 127)可以生成不同的字母(字符样式不同,但编码保持不变)。例如,代码为 0xB8(十进制 184)的符号在西欧语言中表示软音符(下钩),而在俄语中这里是字母 ё。再举个例子:
c
PRT(CharToString(0xA9)); // "©"
PRT(CharToString(0xE6)); // "æ", "ж", 或其他字符
// 取决于您的 Windows 区域设置string ShortToString(ushort code)
该函数将字符的 Unicode 编码转换为单字符字符串。对于 code 参数,可以使用字面值或整数。例如,希腊大写字母“西格玛”(数学公式中的求和符号)可以指定为 0x3A3 或 'Σ'。
c
PRT(ShortToString(0x3A3)); // "Σ"
PRT(ShortToString('Σ')); // "Σ"int StringToShortArray(const string text, ushort &array[], int start = 0, int count = -1)
该函数将字符串转换为 ushort 字符编码序列,并将其复制到数组中的指定位置:从编号为 start 的元素开始(默认为 0,即数组的开头),数量为 count。
请注意:start 参数指的是数组中的位置,而不是字符串中的位置。如果要转换字符串的一部分,必须首先使用 StringSubstr 函数提取它。
如果 count 参数等于 -1(或 WHOLE_ARRAY),则会复制直到字符串末尾的所有字符(包括终止零),或者如果数组是固定大小的,则根据数组的大小复制字符。
对于动态数组,如果需要,它的大小将自动增加。如果动态数组的大小大于字符串的长度,则数组的大小不会减小。
要复制没有终止零的字符,必须显式调用 StringLen 作为 count 参数。否则,数组的长度将比字符串的长度多 1(并且最后一个元素为 0)。
函数返回复制的字符数。
c
...
ushort array1[], array2[]; // 动态数组
ushort text[5]; // 固定大小数组
string alphabet = "ABCDEАБВГД";
// 复制并包含终止符 '0'
PRT(StringToShortArray(alphabet, array1)); // 11
ArrayPrint(array1); // 65 66 67 68 69 1040 1041 1042 1043 1044 0
// 复制且不包含终止符 '0'
PRT(StringToShortArray(alphabet, array2, 0, StringLen(alphabet))); // 10
ArrayPrint(array2); // 65 66 67 68 69 1040 1041 1042 1043 1044
// 复制到固定数组
PRT(StringToShortArray(alphabet, text)); // 5
ArrayPrint(text); // 65 66 67 68 69
// 复制超出数组之前的限制
// (元素 [11-19] 将是随机的)
PRT(StringToShortArray(alphabet, array2, 20)); // 11
ArrayPrint(array2);
/*
[ 0] 65 66 67 68 69 1040 1041 1042
1043 1044 0 0 0 0 0 14245
[16] 15102 37754 48617 54228 65 66 67 68
69 1040 1041 1042 1043 1044 0
*/请注意,如果复制的位置超出了数组的大小,那么中间的元素将被分配但不会初始化。因此,它们可能包含随机数据(上面以黄色突出显示)。
string ShortArrayToString(const ushort &array[], int start = 0, int count = -1)
该函数将包含字符编码的数组的一部分转换为字符串。数组元素的范围分别由参数 start 和 count 设置,即起始位置和数量。start 参数必须在 0 到数组中元素数量减 1 之间。如果 count 等于 -1(或 WHOLE_ARRAY),则会复制直到数组末尾的所有元素,或者直到遇到第一个零。
使用 StringSymbols.mq5 中的相同示例,我们尝试将数组转换为 array2 字符串,其大小为 30。
c
...
string s = ShortArrayToString(array2, 0, 30);
PRT(s); // "ABCDEАБВГД", 这里可能会出现额外的随机字符因为在 array2 数组中,字符串 "ABCDEABCD" 被复制了两次,具体来说,第一次复制到了数组的开头,第二次复制到了偏移量为 20 的位置,所以中间的字符将是随机的,并且可能会形成一个比我们预期更长的字符串。
int StringToCharArray(const string text, uchar &array[], int start = 0, int count = -1, uint codepage = CP_ACP)
该函数将文本字符串转换为单字节字符序列,并将其复制到数组中的指定位置:从编号为 start 的元素开始(默认为 0,即数组的开头),数量为 count。复制过程将字符从 Unicode 转换为选定的代码页 codepage — 默认情况下为 CP_ACP,这意味着 Windows 操作系统的语言(下面会详细介绍)。
如果 count 参数等于 -1(或 WHOLE_ARRAY),则会复制直到字符串末尾的所有字符(包括终止零),或者如果数组是固定大小的,则根据数组的大小复制字符。
对于动态数组,如果需要,它的大小将自动增加。如果动态数组的大小大于字符串的长度,则数组的大小不会减小。
要复制没有终止零的字符,必须显式调用 StringLen 作为 count 参数。
函数返回复制的字符数。
有关 codepage 参数的有效代码页列表,请参阅文档。以下是一些广泛使用的 ANSI 代码页:
| 语言 | 代码 |
|---|---|
| 中欧拉丁语 | 1250 |
| 西里尔语 | 1251 |
| 西欧拉丁语 | 1252 |
| 希腊语 | 1253 |
| 土耳其语 | 1254 |
| 希伯来语 | 1255 |
| 阿拉伯语 | 1256 |
| 波罗的海语 | 1257 |
因此,在使用西欧语言的计算机上,CP_ACP 为 1252,例如,在使用俄语的计算机上,它为 1251。
在转换过程中,一些字符可能会在信息丢失的情况下进行转换,因为 Unicode 表比 ANSI 表大得多(每个 ANSI 代码表有 256 个字符)。
在所有 CP_*** 常量中,CP_UTF8 具有特别重要的意义。它通过可变长度编码允许正确保留本国字符:生成的数组仍然存储字节,但每个本国字符可以跨越多个字节,并以特殊格式书写。因此,数组的长度可能会明显大于字符串的长度。UTF-8 编码在互联网和各种软件中被广泛使用。顺便说一下,UTF 代表 Unicode 转换格式,还有其他变体,特别是 UTF-16 和 UTF-32。
在熟悉了“反向”函数 CharArrayToString 之后,我们将考虑 StringToCharArray 的示例:它们的工作必须结合起来进行演示。
string CharArrayToString(const uchar &array[], int start = 0, int count = -1, uint codepage = CP_ACP)
该函数将字节数组或其一部分转换为字符串。数组必须包含特定编码的字符。数组元素的范围分别由参数 start 和 count 设置,即起始位置和数量。start 参数必须在 0 到数组中元素数量之间。当 count 等于 -1(或 WHOLE_ARRAY)时,会复制直到数组末尾的所有元素,或者直到遇到第一个零。
让我们看看 StringToCharArray 和 CharArrayToString 函数在不同代码页设置下处理不同国家字符时的工作情况。为此准备了一个测试脚本 StringCodepages.mq5。
将使用两行文本作为测试对象 — 一行是俄语,一行是德语:
c
void OnStart()
{
Print("Locales");
uchar bytes1[], bytes2[];
string german = "straßenführung";
string russian = "Russian text";
...我们将把它们复制到数组 bytes1 和 bytes2 中,然后再将它们恢复为字符串。
首先,使用欧洲代码页 1252 转换德语文本。
c
...
StringToCharArray(german, bytes1, 0, WHOLE_ARRAY, 1252);
ArrayPrint(bytes1);
// 115 116 114 97 223 101 110 102 252 104 114 117 110 103 0在欧洲版本的 Windows 上,这等同于使用默认参数调用更简单的函数,因为在那里 CP_ACP = 1252:
c
StringToCharArray(german, bytes1);然后通过以下调用从数组中恢复文本,并确保与原始文本匹配:
c
...
PRT(CharArrayToString(bytes1, 0, WHOLE_ARRAY, 1252));
// CharArrayToString(bytes1,0,WHOLE_ARRAY,1252)='straßenführung'现在让我们尝试用相同的欧洲编码转换俄语文本(或者在 CP_ACP 设置为 1252 作为默认代码页的 Windows 环境中调用 StringToCharArray(english, bytes2)):
c
...
StringToCharArray(russian, bytes2, 0, WHOLE_ARRAY, 1252);
ArrayPrint(bytes2);
// 63 63 63 63 63 63 63 32 63 63 63 63 63 0在这里已经可以看到转换过程中出现了问题,因为 1252 代码页中没有西里尔字符。从数组恢复字符串清楚地显示了问题的本质:
c
...
PRT(CharArrayToString(bytes2, 0, WHOLE_ARRAY, 1252));
// CharArrayToString(bytes2,0,WHOLE_ARRAY,1252)='??????? ?????'让我们在一个假设的俄语环境中重复这个实验,即我们将使用西里尔语代码页 1251 来回转换这两个字符串。
c
...
StringToCharArray(russian, bytes2, 0, WHOLE_ARRAY, 1251);
// 在俄语 Windows 上,此调用等同于更简单的调用
// StringToCharArray(russian, bytes2);
// 因为 CP_ACP = 1251
ArrayPrint(bytes2); // 这次字符编码是有意义的
// 208 243 241 241 234 232 233 32 210 229 234 241 242 0
// 恢复字符串并确保与原始字符串匹配
PRT(CharArrayToString(bytes2, 0, WHOLE_ARRAY, 1251));
// CharArrayToString(bytes2,0,WHOLE_ARRAY,1251)='Русский Текст'
// 对于德语文本...
StringToCharArray(german, bytes1, 0, WHOLE_ARRAY, 1251);
ArrayPrint(bytes1);
// 115 116 114 97 63 101 110 102 117 104 114 117 110 103 0
// 如果我们将 bytes1 的此内容与之前的版本进行比较,
// 很容易看出有几个字符受到了影响;情况如下:
// 115 116 114 97 223 101 110 102 252 104 114 117 110 103 0
// 恢复字符串以直观地查看差异:
PRT(CharArrayToString(bytes1, 0, WHOLE_ARRAY, 1251));
// CharArrayToString(bytes1,0,WHOLE_ARRAY,1251)='stra?enfuhrung'
// 特定的德语字符已损坏因此,单字节编码的脆弱性显而易见。
最后,让我们为两个测试字符串启用 CP_UTF8 编码。这部分示例无论 Windows 设置如何都能稳定工作。
c
...
StringToCharArray(german, bytes1, 0, WHOLE_ARRAY, CP_UTF8);
ArrayPrint(bytes1);
// 115 116 114 97 195 159 101 110 102 195 188 104 114 117 110 103 0
PRT(CharArrayToString(bytes1, 0, WHOLE_ARRAY, CP_UTF8));
// CharArrayToString(bytes1,0,WHOLE_ARRAY,CP_UTF8)='straßenführung'
StringToCharArray(russian, bytes2, 0, WHOLE_ARRAY, CP_UTF8);
ArrayPrint(bytes2);
// 208 160 209 131 209 129 209 129 208 186 208 184 208 185
// 32 208 162 208 181 208 186 209 129 209 130 0
PRT(CharArrayToString(bytes2, 0, WHOLE_ARRAY, CP_UTF8));
// CharArrayToString(bytes2,0,WHOLE_ARRAY,CP_UTF8)='Русский Текст'请注意,两个 UTF-8 编码的字符串所需的数组都比 ANSI 编码的数组大。此外,俄语字符串的数组实际上变长了两倍,因为现在所有字母都占用 2 个字节。有兴趣的人可以在公开资源中找到 UTF-8 编码具体工作方式的详细信息。在本书的背景下,对我们来说重要的是 MQL5 API 提供了现成的函数来进行相关操作。
通过这些函数,开发者可以更灵活地处理字符串中的字符,无论是进行字符级别的修改、提取字符编码,还是在不同编码之间进行转换,都能找到合适的工具来满足需求。在实际编程中,根据具体的应用场景和数据来源,正确选择和使用这些函数对于确保字符串处理的正确性和高效性至关重要。同时,了解不同编码的特点和适用范围,也有助于避免因编码问题导致的数据丢失或显示错误等问题。
通用格式化数据输出为字符串
在生成要显示给用户、保存到文件或通过互联网发送的字符串时,可能需要在其中包含多个不同类型变量的值。 可以通过将所有变量显式转换为(字符串)类型并将得到的字符串相加来解决此问题,但在这种情况下,MQL 代码指令会很长且难以理解。 使用 StringConcatenate 函数可能会更方便,但这种方法并不能完全解决问题。
事实上,一个字符串通常不仅包含变量,还包含一些文本插入内容,这些内容充当连接纽带,并为整体消息提供正确的结构。 结果是格式化文本片段与变量混合在一起。 这种代码很难维护,这与编程中一个著名的原则相悖:内容与表示的分离。
针对这个问题有一个特殊的解决方案:StringFormat 函数。
同样的方案也适用于另一个 MQL5 API 函数:PrintFormat。
string StringFormat(const string format, ...)该函数根据指定的格式将任意内置类型的参数转换为字符串。 第一个参数是要准备的字符串模板,其中以特殊方式指示了插入变量的位置,并确定了它们的输出格式。 这些控制命令可以与纯文本穿插,纯文本会原封不动地复制到输出字符串中。 后续的函数参数(用逗号分隔)按照模板中为它们预留的顺序和类型列出所有变量。

格式字符串与 StringFormat 参数的交互
格式字符串与 StringFormat 参数的交互
字符串中的每个变量插入点都用一个格式说明符标记:字符 %,在它之后可以指定一些设置。
格式字符串从左到右进行解析。 当遇到第一个说明符(如果有的话)时,格式字符串之后的第一个参数的值会根据指定的设置进行转换并添加到结果字符串中。 第二个说明符会导致第二个参数被转换并输出,依此类推,直到格式字符串结束。 模式中说明符之间的所有其他字符都会原封不动地复制到结果字符串中。
模板中可能不包含任何说明符,也就是说,它可以是一个简单的字符串。 在这种情况下,除了字符串之外,还需要向函数传递一个虚拟参数(该参数不会被放入字符串中)。
如果要在模板中显示百分号,则应连续写两次 %%。 如果 % 符号没有重复写,那么 % 后面的接下来几个字符总是会被解析为一个说明符。
说明符的一个必需属性是一个符号,该符号指示下一个函数参数的预期类型和解释。 我们姑且将这个符号称为 T。 那么,在最简单的情况下,一个格式说明符看起来像 %T。
在一般形式下,说明符可以由更多字段组成(可选字段用方括号表示):
%[Z][W][.P][M]T每个字段都执行其功能,并采用一个允许的值。 接下来,我们将逐步介绍所有字段。
类型 T
对于整数,可以使用以下字符作为 T,并对相应数字在字符串中的显示方式进行说明:
c— Unicode 字符C— ANSI 字符d,i— 有符号十进制数o— 无符号八进制数u— 无符号十进制数x— 无符号十六进制数(小写)X— 无符号十六进制数(大写字母)
请记住,根据内部数据存储方法,整数类型还包括内置的 MQL5 类型 datetime、color、bool 和枚举类型。
对于实数,以下符号可用作 T:
e— 带指数的科学计数法(小写e)E— 带指数的科学计数法(大写E)f— 普通格式g— 类似于f或e(选择最紧凑的形式)G— 类似于f或E(选择最紧凑的形式)a— 带指数的十六进制科学计数法(小写)A— 带指数的十六进制科学计数法(大写字母)
最后,对于字符串,T 字符只有一个可用版本:s。
整数大小 M
对于整数类型,可以通过在 T 前面加上以下字符或字符组合之一(我们将它们概括为字母 M)来额外显式指定变量的字节大小:
h— 2 字节(short,ushort)l(小写L) — 4 字节(int,uint)I32(大写i) — 4 字节(int,uint)ll(两个小写L) — 8 字节(long)I64(大写i) — 8 字节(long,ulong)
宽度 W
W 字段是一个非负十进制数,它指定为格式化值预留的最小字符空间数。 如果变量的值占用的字符数较少,则会在左侧或右侧添加相应数量的空格。 根据对齐方式(请参阅 Z 字段中的标志 —)选择左侧或右侧。 如果存在 0 标志,则会在输出值前面添加相应数量的零。 如果要输出的字符数大于指定的宽度,则宽度设置将被忽略,并且输出值不会被截断。
如果指定 * 作为宽度,则应在传递的参数列表中指定输出值的宽度。 它应该是在要格式化的变量之前位置的一个 int 类型的值。
精度 P
P 字段也包含一个非负十进制数,并且总是前面有一个点 .。 对于整数 T,此字段指定最小有效数字位数。 如果值占用的位数较少,则在前面添加零。
对于实数,P 指定小数位数(默认值为 6),g 和 G 说明符除外,对于它们,P 是有效数字的总数(尾数和小数部分)。
对于字符串,P 指定要显示的字符数。 如果字符串长度超过精度值,则字符串将显示为被截断。
如果指定 * 作为精度,其处理方式与宽度相同,但控制的是精度。
固定宽度和/或精度,再加上右对齐,使得能够以整齐的列形式显示值。
标志 Z
最后,Z 字段描述标志:
-(减号) — 在指定宽度内左对齐(如果没有该标志,则进行右对齐);+(加号) — 在值前面无条件显示+或-符号(如果没有此标志,仅对负值显示-);0— 如果输出值小于指定宽度,则在输出值前面添加零;(空格) — 如果值是有符号的并且为正,则在显示的值前面放置一个空格;#— 控制八进制和十六进制数前缀在o、x或X格式中的显示(例如,对于x格式,在显示的数字前面添加前缀0x,对于X格式 — 前缀0X),控制实数(e、E、a或A格式)中带有零小数部分的小数点的显示,以及一些其他细微差别。
有关向字符串进行格式化输出的更多可能性,可以在文档中了解。
函数参数的总数不能超过 64 个。
如果传递给函数的参数数量大于说明符的数量,则多余的参数将被忽略。
如果格式字符串中的说明符数量大于参数数量,则系统将尝试用零代替缺失的数据进行显示,但对于字符串说明符,会嵌入一个文本警告(“缺少字符串参数”)。
如果值的类型与相应说明符的类型不匹配,系统将尝试根据格式从变量中读取数据并显示得到的值(由于对实际数据的内部位表示的错误解释,显示的值可能看起来很奇怪)。 在字符串的情况下,结果中可能会嵌入一个警告(“传递了非字符串”)。
让我们使用脚本 StringFormat.mq5 来测试这个函数。
首先,让我们尝试 T 和数据类型说明符的不同选项。
PRT(StringFormat("[Infinity Sign] Unicode (ok): %c; ANSI (overflow): %C",
'∞', '∞'));
PRT(StringFormat("short (ok): %hi, short (overflow): %hi",
SHORT_MAX, INT_MAX));
PRT(StringFormat("int (ok): %i, int (overflow): %i",
INT_MAX, LONG_MAX));
PRT(StringFormat("long (ok): %lli, long (overflow): %i",
LONG_MAX, LONG_MAX));
PRT(StringFormat("ulong (ok): %llu, long signed (overflow): %lli",
ULONG_MAX, ULONG_MAX));这里既表示了正确的说明符,也表示了不正确的说明符(不正确的在每个指令中排在第二个,并标记为“overflow”,因为传递的值不适合格式类型)。
日志中的结果如下(这里和下面长行的换行是为了便于发布):
StringFormat(Plain string,0)='Plain string'
StringFormat([Infinity Sign] Unicode: %c; ANSI: %C,'∞','∞')=
'[Infinity Sign] Unicode (ok): ∞; ANSI (overflow): '
StringFormat(short (ok): %hi, short (overflow): %hi,SHORT_MAX,INT_MAX)=
'short (ok): 32767, short (overflow): -1'
StringFormat(int (ok): %i, int (overflow): %i,INT_MAX,LONG_MAX)=
'int (ok): 2147483647, int (overflow): -1'
StringFormat(long (ok): %lli, long (overflow): %i,LONG_MAX,LONG_MAX)=
'long (ok): 9223372036854775807, long (overflow): -1'
StringFormat(ulong (ok): %llu, long signed (overflow): %lli,ULONG_MAX,ULONG_MAX)=
'ulong (ok): 18446744073709551615, long signed (overflow): -1'以下所有指令都是正确的:
PRT(StringFormat("ulong (ok): %I64u", ULONG_MAX));
PRT(StringFormat("ulong (HEX): %I64X, ulong (hex): %I64x",
1234567890123456, 1234567890123456));
PRT(StringFormat("double PI: %f", M_PI));
PRT(StringFormat("double PI: %e", M_PI));
PRT(StringFormat("double PI: %g", M_PI));
PRT(StringFormat("double PI: %a", M_PI));
PRT(StringFormat("string: %s", "ABCDEFGHIJ"));它们的执行结果如下:
StringFormat(ulong (ok): %I64u,ULONG_MAX)=
'ulong (ok): 18446744073709551615'
StringFormat(ulong (HEX): %I64X, ulong (hex): %I64x,1234567890123456,1234567890123456)=
'ulong (HEX): 462D53C8ABAC0, ulong (hex): 462d53c8abac0'
StringFormat(double PI: %f,M_PI)='double PI: 3.141593'
StringFormat(double PI: %e,M_PI)='double PI: 3.141593e+00'
StringFormat(double PI: %g,M_PI)='double PI: 3.14159'
StringFormat(double PI: %a,M_PI)='double PI: 0x1.921fb54442d18p+1'
StringFormat(string: %s,ABCDEFGHIJ)='string: ABCDEFGHIJ'现在让我们看看各种修饰符。
使用右对齐(默认)和固定字段宽度(字符数),我们可以使用不同的选项在结果字符串的左侧进行填充:用空格或零。 此外,对于任何对齐方式,都可以启用或禁用值的符号的显式指示(这样不仅对负值显示减号,对正值也显示加号)。
PRT(StringFormat("space padding: %10i", SHORT_MAX));
PRT(StringFormat("0-padding: %010i", SHORT_MAX));
PRT(StringFormat("with sign: %+10i", SHORT_MAX));
PRT(StringFormat("precision: %.10i", SHORT_MAX));我们在日志中得到以下内容:
StringFormat(space padding: %10i,SHORT_MAX)='space padding: 32767'
StringFormat(0-padding: %010i,SHORT_MAX)='0-padding: 0000032767'
StringFormat(with sign: %+10i,SHORT_MAX)='with sign: +32767'
StringFormat(precision: %.10i,SHORT_MAX)='precision: 0000032767'要左对齐,必须使用 -(减号)标志,将字符串添加到指定宽度的操作发生在右侧:
PRT(StringFormat("no sign (default): %-10i", SHORT_MAX));
PRT(StringFormat("with sign: %+-10i", SHORT_MAX));结果:
StringFormat(no sign (default): %-10i,SHORT_MAX)='no sign (default): 32767 '
StringFormat(with sign: %+-10i,SHORT_MAX)='with sign: +32767 '如果需要,我们可以显示或隐藏值的符号(默认情况下,仅对负值显示减号),为正值添加空格,从而在需要以列形式显示变量时确保相同的格式化:
PRT(StringFormat("default: %i", SHORT_MAX)); // 标准
PRT(StringFormat("default: %i", SHORT_MIN));
PRT(StringFormat("space : % i", SHORT_MAX)); // 为正值添加额外空格
PRT(StringFormat("space : % i", SHORT_MIN));
PRT(StringFormat("sign : %+i", SHORT_MAX)); // 强制输出符号
PRT(StringFormat("sign : %+i", SHORT_MIN));日志中的内容如下:
StringFormat(default: %i,SHORT_MAX)='default: 32767'
StringFormat(default: %i,SHORT_MIN)='default: -32768'
StringFormat(space : % i,SHORT_MAX)='space : 32767'
StringFormat(space : % i,SHORT_MIN)='space : -32768'
StringFormat(sign : %+i,SHORT_MAX)='sign : +32767'
StringFormat(sign : %+i,SHORT_MIN)='sign : -32768'现在让我们比较宽度和精度对实数的影响。
PRT(StringFormat("double PI: %15.10f", M_PI));
PRT(StringFormat("double PI: %15.10e", M_PI));
PRT(StringFormat("double PI: %15.10g", M_PI));
PRT(StringFormat("double PI: %15.10a", M_PI));
// 默认精度 = 6
PRT(StringFormat("double PI: %15f", M_PI));
PRT(StringFormat("double PI: %15e", M_PI));
PRT(StringFormat("double PI: %15g", M_PI));
PRT(StringFormat("double PI: %15a", M_PI));结果:
StringFormat(double PI: %15.10f,M_PI)='double PI: 3.1415926536'
StringFormat(double PI: %15.10e,M_PI)='double PI: 3.1415926536e+00'
StringFormat(double PI: %15.10g,M_PI)='double PI: 3.141592654'
StringFormat(double PI: %15.10a,M_PI)='double PI: 0x1.921fb54443p+1'
StringFormat(double PI: %15f,M_PI)='double PI: 3.141593'
StringFormat(double PI: %15e,M_PI)='double PI: 3.141593e+00'
StringFormat(double PI: %15g,M_PI)='double PI: 3.14159'
StringFormat(double PI: %15a,M_PI)='double PI: 0x1.921fb54442d18p+1'如果未指定显式宽度,则输出的值不会用空格填充。