如何避免过度拟合-维度诅咒
一、过度拟合的定义
什么是过度拟合?它是指模型过于紧密或精确地匹配特定数据集,导致无法良好拟合其他数据或预测未来观察结果的现象。通俗来说,就像死记硬背历史考试题,遇到新题目却无法解答。
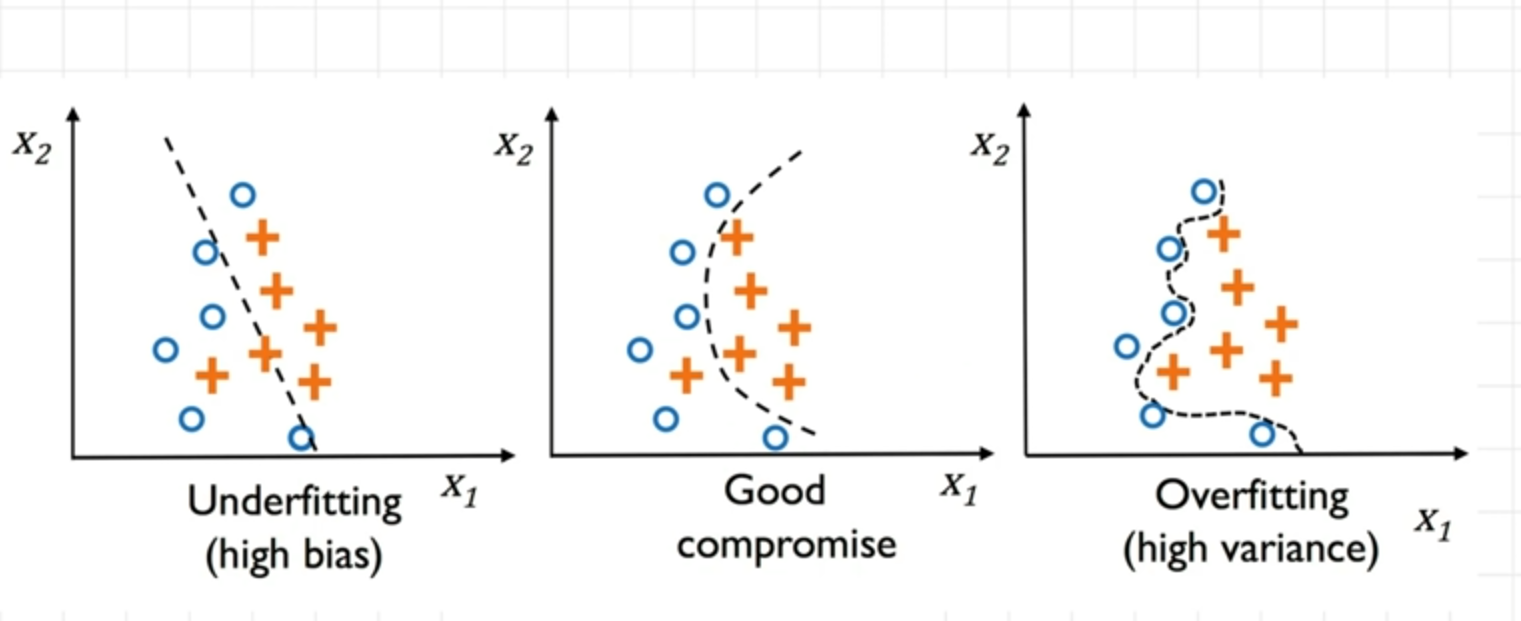
- 欠拟合:模型未能提取有效数据特征(如图1)。
- 合理拟合:模型平衡拟合效果,无生硬匹配(如图2)。
- 过度拟合:模型生硬迎合数据细节,泛化能力差(如图3)。
二、量化交易中的过度拟合问题
在量化策略研发中,参数优化的核心难点是避免过度拟合。以样本内(in-sample和样本外(out-of-sample测试为例:
1. 样本内与样本外测试
- 样本内数据:用于策略初步测试和参数优化(“学习数据”)。
- 样本外数据:验证优化后的参数在新数据上的表现(“测试数据”)。
示例:将2012-2017年数据作为样本内进行参数优化,2018-2023年数据作为样本外验证策略表现。

三、参数优化的关键要点
(一)优化参数的选择
1. 参数范围需符合策略逻辑
参数范围应基于策略的理论基础,覆盖目标行情。
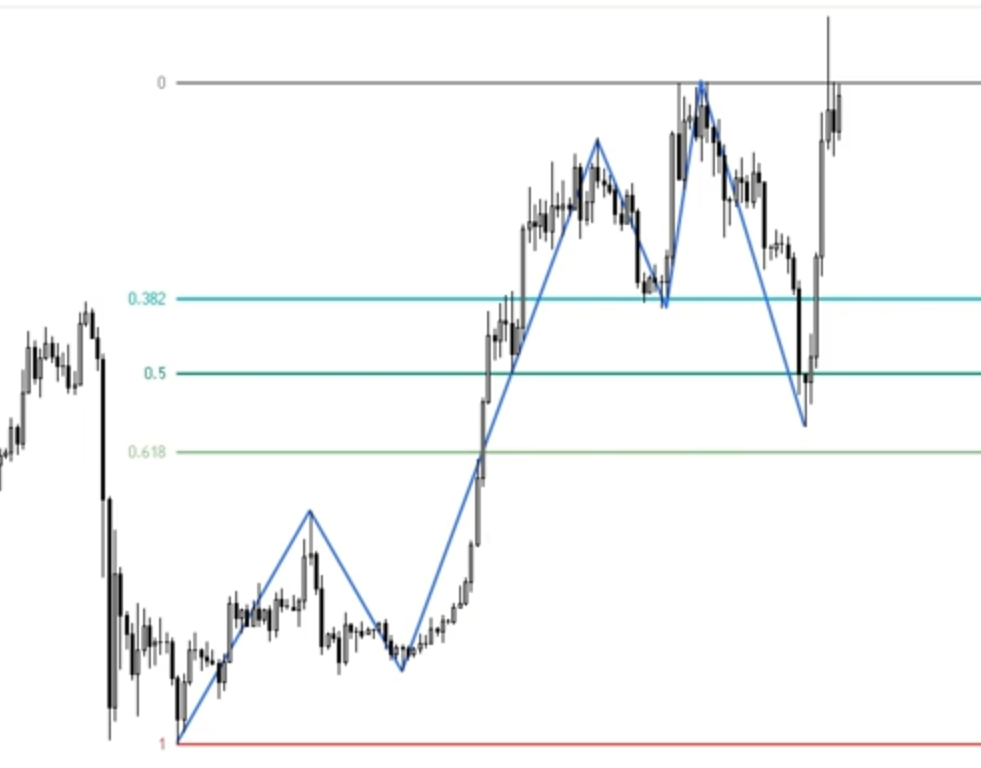
- 案例:斐波那契回撤策略的参数范围应围绕0.382、0.5、0.618等合理水平,而非盲目扩大至1.5、2.5等脱离策略逻辑的数值。
- 原则:不属于策略目标的行情段应舍弃,避免选出参数孤岛。
2. 步长设置避免过细
步长过小会使模型过度迎合历史数据细节,增加过拟合风险。
- 案例:布林带参数从10开始,步长设为10(10, 20, 30…)优于步长1(10, 11, 12…),后者易陷入“数据凹合”。
3. 控制可优化参数的数量(自由度)
- 维数诅咒:参数过多(高自由度)会导致信息稀疏,模型仅拟合局部数据,泛化能力差。
- 建议:最多优化3-5个参数,避免一次性优化超过5个参数。简单策略往往更稳健。
(二)优化结果的评估方法
1. 样本内与样本外分段测试
- 步骤:
- 划分数据:如2012-2017年(样本内训练),2018-2023年(样本外测试)。
- 市场扫描:通过评价函数(如“采收率”=利润/最大回撤)筛选有效参数。
- 验证标准:样本外表现需达到合理阈值(如采收率随样本内年份增加而递增,6年数据要求采收率>3)。
2. 三数据集划分(进阶方法)
- 训练集:用于策略开发和初步参数优化。
- 验证集:模拟实盘前的缓冲测试,避免过度依赖单一测试集。
- 测试集:最终验证策略泛化能力。
示例:假设当前是2024年,用2012-2017年(训练集)、2018-2021年(验证集)、2022-2023年(测试集)分阶段验证。

四、总结
实战中 按照 样本内与样本外测试 比 三数据集更快,这样效率更高,能省出时间开发更多的策略, 同时配合一下4点即可
- 样本量要大
- 参数范围合理
- 步长不要太小
- 参数数量不超过3个